The Language Problem: Why Your Website Can't Talk to AI — And What to Do About It
The systems deciding whether to recommend your business don't read your homepage the way a buyer does. They parse it the way a customs officer reads a passport — looking for verified, structured facts. Here's why default plugin schema fails that test, and what fixes it.
Mark Abplanalp
June 14, 2026
Imagine you're traveling in Japan. You don't speak Japanese. A stranger stops you, and you need to explain your business — not just what you sell, but who your customers are, where you're located, your hours, what makes you trustworthy, how someone contacts you, and why you're better than the three other businesses two blocks away.
You'd try. Hand gestures, broken phrases, a translation app that keeps getting things wrong. You might get across the basics — “I sell windows,” “Post Falls, Idaho,” “call this number.” But the nuance? The credentials? The complete picture that would make a stranger confidently say “yes, go to this specific business”? Lost in translation. That stranger would probably shrug and say “I don't know” rather than risk a bad recommendation.
That is your website right now, in front of an AI system.
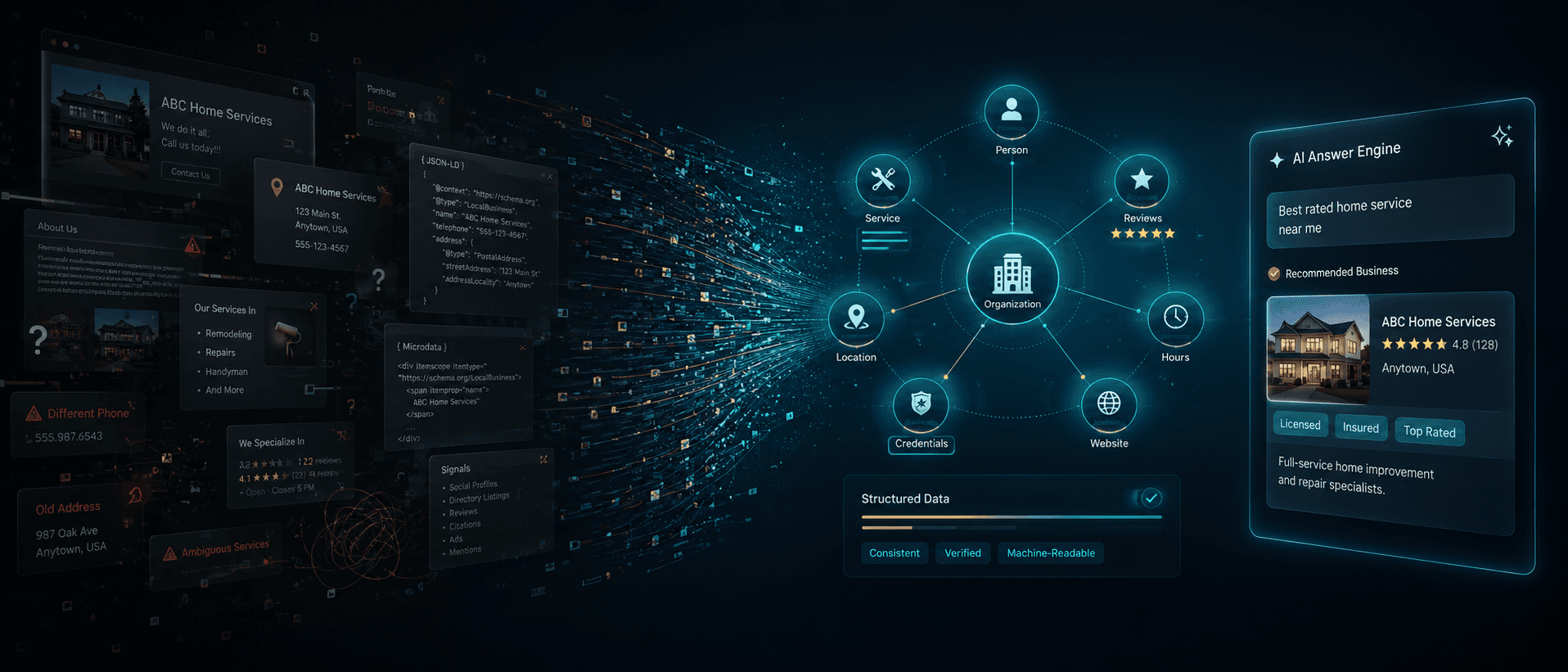
What AI Systems Actually Do When They “Read” Your Website
Most owners think about their website the way they think about a billboard — something humans look at. But the systems now deciding whether to recommend your business are not human. They're language models, knowledge graphs, and answer engines: ChatGPT, Google's AI Overviews, Bing Copilot, Perplexity. They parse your page the way a customs officer reads a passport — looking for verified, structured, machine-readable facts that confirm who you are and whether you can be trusted.
When those systems process a query like “who's the best window treatment company in Post Falls,” they're not keyword-matching. They're looking for a verifiable entity. Google resolves the entities on a page against its Knowledge Graph — deciding, for example, that this “Apple” is the company, not the fruit — and uses that resolved entity layer to decide which pages deserve to surface (Jottler, 2026). A business the system can identify, confirm, and cross-reference against authoritative sources is one it can recommend with confidence.
“Confidence” is the key word. When the structured data about your business is thin, ambiguous, or contradictory — which it almost certainly is on WordPress, Wix, or Squarespace with default settings — the system has a harder time placing you. Entity recognition runs on three signals working together: structured data ( Schema.org markup), corroborating mentions across authoritative sources, and a consistent identity — the same name, description, and sameAs URLs everywhere (Jottler, 2026). When those signals are weak, the system surfaces the business it can most clearly understand — and it names that business instead.
The Plugin Problem
Every major WordPress SEO plugin — Yoast, Rank Math, Schema Pro — generates structured data automatically. To be fair: the better plugins do build a connected graph. Yoast automatically generates a unified @graph on every page, wiring together Organization, WebSite, WebPage, Article, and Person through stable @id anchors. So the issue isn't that plugins “can't build a graph.” The real gap is three things plugins genuinely don't do well — and each is independently verifiable.
First: the graph is shallow and generic. The plugin builds a templated graph. In one analysis of 150 independent agency websites, 88% relied on generic LocalBusiness markup rather than a specific subtype (LovedByAI, 2026). To an AI, a generic LocalBusiness “could be a pizza shop or a dry cleaner” — it lacks the semantic weight of a precise type. What plugins don't express out of the box is what actually wins recommendations: deep credential chains tied to issuing authorities, custom knowsAbout topical authority, rich citation arrays, and precise geographic depth (DEV Community, 2026).
Second: most of these sites can't be read on cold crawl. This is the more decisive problem — even a perfect graph is invisible if the AI crawler can't read it without executing JavaScript. It gets its own section below.
Third: a plugin fills in blanks; it doesn't make entity-architecture decisions. It can't decide which specific Schema.org subtype best describes you, which credentials to surface, which topics establish your authority, or how to model your service geography. That judgment — knowing what the schema should say — is the actual work, and no plugin does it for you.
Why This Is the Moment That Matters
For the first twenty years of the commercial web, much of Google's job was to match keywords. Your content was the product — volume of words, keywords targeted, backlinks earned. That world still exists, but it's changing fast. AI Overviews, ChatGPT, Perplexity, and Bing Copilot generate one synthesized answer and point to the handful of sources that informed it. Perplexity typically synthesizes from roughly 5 to 10 sources and cites only a few (AI Labs Audit, 2026), and Google's AI Overviews usually surface just 3 to 6 source cards (AEO Hunt, 2026). The output of a search is condensing from a page of options into a small set of cited entities.
The businesses that make that cut aren't necessarily the ones with the most content. They're the ones the AI can read clearly, verify, and select with confidence. Citation selection is based on extractability and entity authority — not raw ranking position. A page can rank first organically and never be cited; a page on page two can be the primary cited source (Project36, 2025). Meanwhile the web is being flooded with AI-generated content at unprecedented scale. The supply of content is effectively infinite. The number of cited entities is small.
What KodeCite Builds Instead
KodeCite doesn't rely on platforms or plugins. We build your website at the code level — Next.js, deployed on Vercel's edge — and engineer your structured data the way a software architect engineers a system. The modern best-practice pattern is exactly this: declare all entities in a single @graph block with cross-referenced @id URIs, letting AI systems reconstruct the relationships between them — an approach that has overtaken the older “one schema block per page” method (DEV Community, 2026). That entity graph declares:
- Who you are — the precise Schema.org subtype that applies, not a generic catch-all. The more specific the type, the more accurately AI systems categorize and recommend you.
- What you're credentialed to do — designations and certifications, made machine-readable and connected to the issuing authority where possible (for a licensed agent in Idaho, the Idaho Real Estate Commission).
- Where you operate — not just an address, but precise
areaServed(a GeoCircle of latitude/longitude plus radius, or specific geographic identifiers) so AI knows exactly where you work. - Who else agrees you're real — the
sameAslayer of verified external profiles (Google Business Profile, BBB, licensing records, Wikidata). Bidirectional links are corroborative claims; one-directional links are unverified assertions (Ibrahim Anwar). - What you're expert in — the
knowsAboutproperty and a content-cluster architecture that signals topical authority in a specific geography. - How to contact and transact — structured, unambiguous contact and service pathways AI systems can extract directly.
This is what it means for your website to speak the native language fluently — not broken phrases and a hope that the AI pieces it together, but a complete, precise declaration of your business identity that an AI system can traverse, verify, and cite.
Why Code-Level Rendering Matters as Much as the Schema
There's a second half to this problem: even perfect schema is useless if the AI crawler can't read it on the first request. Most AI crawlers do not execute JavaScript. Vercel's large-scale analysis of AI crawler traffic — covering hundreds of millions of requests — found that none of the major AI crawlers (OpenAI's GPTBot, Anthropic's ClaudeBot, Perplexity's PerplexityBot, and others) render JavaScript. ChatGPT and Claude crawlers download JavaScript files (about 11.5% and 23.8% of requests respectively), but they don't run them (Vercel, 2024). Search Engine Journal reached the same conclusion: server-side rendering is “a requirement for AI search visibility, not an optimization.”
The implication: if your content, schema, and internal links only appear after client-side JavaScript executes, they may be invisible to the systems powering ChatGPT, Claude, and Perplexity. Server-side rendering — the default in a properly built Next.js application — delivers complete, readable HTML on the first request. You can test your own site in five minutes: run curl on a key page (or use “View Source,” not “Inspect Element”). If your core content and schema aren't in the raw response, the AI crawlers can't see them either.
The Difference That's Already Showing Up
We've watched this play out. Take Shirin Abplanalp, a licensed REALTOR® with 11 years of experience and more than 100 transactions closed — but all of that was built in Bend, Oregon. When she relocated and launched on this infrastructure in early 2026, she was brand new to North Idaho: no local closings, no Google Business Profile, competing against agents who had worked that market for two decades.
Within roughly eight weeks, the AI engines were treating her site as a primary source for North Idaho relocation queries. Bing Copilot built entire city-comparison answers almost wholly from her data — citing the site for nearly every figure: population, home values, days-on-market, commute times. ChatGPT named her site as a reference. Perplexity cited her articles directly. On an eight-week-old site with zero Idaho closings — not because she'd outspent anyone, but because her entity graph was clean, complete, and readable on cold crawl in a way that competing plugin-built sites were not.
This is consistent with how these systems are documented to behave: citation goes to the source the engine can extract cleanly and verify as an authoritative entity — not to whoever has the longest local track record (Project36, 2025). The infrastructure created the local authority before the local track record existed. That's the difference.
The Question Worth Asking Right Now
If you're reading this on a WordPress site, or your designer recently “added schema” using a plugin, the question is simple: what exactly does an AI system see when it crawls your business? Not what your site looks like to a human visitor — what it looks like to a machine deciding whether to recommend you. A Machine Read shows you the real picture: your schema architecture, entity completeness, NAP consistency across directories, and cold-crawl readability — not the one a plugin dashboard implies.
Frequently Asked Questions
Why doesn't my SEO agency solve this problem?
Traditional SEO was built for ranking on a list of ten results, and much of the industry still optimizes for that — backlinks, keywords, titles. Those still matter for organic search, but AI recommendations lean on a different signal: entity verification and structured trust. Many agencies lack the engineering capacity to build custom entity graphs at the code level, and the plugins they rely on tend to produce generic output.
What's the difference between schema and an entity graph?
Schema is a vocabulary — standardized terms from Schema.org that describe things in machine-readable ways. An entity graph is an architecture that uses that vocabulary to connect stable identities — your business, founder, website, content — through permanent @id anchors AI systems can traverse. Plugin schema often uses the vocabulary but builds only a shallow, templated graph.
Does this mean my WordPress site can never rank in AI?
WordPress itself isn't disqualifying. The problems are (1) generic plugin-generated schema and (2) JavaScript-dependent rendering, which creates a cold-crawl gap. Sophisticated developers can address parts of this on WordPress; what's harder is the full entity-graph architecture — stable @id anchors, a single @graph source of truth, and reliable server-side rendering on cold crawl.
How long does it take to see results?
It depends on your market. In a less saturated market, meaningful AI citations can appear within weeks; in competitive markets, longer. What's consistent is that the entity graph compounds — every new piece of content that correctly references the canonical graph strengthens the signal, and the infrastructure keeps working after launch.
What exactly does a Machine Read show me?
A technical audit of your current AI visibility: schema completeness, cold-crawl performance (can AI read your content without executing JavaScript), entity verification (do your directories, Google Business Profile, and schema agree on your NAP), your current citation status in ChatGPT, Perplexity, and Google AI Mode, and a prioritized gap list.
Sources
- Vercel — The rise of the AI crawler
- Search Engine Journal — The Technical SEO Audit Needs a New Layer
- Launchmind — SSR and server-side rendering for AI crawlers
- Jottler — Knowledge Graph SEO: Entity Optimization for AI Search
- DEV Community — Schema.org + JSON-LD: the complete pattern reference
- DEV Community — Schema Markup JSON-LD for Local Businesses
- DEV Community — Customizing Yoast SEO's structured data with the schema API
- Yoast developer portal — Schema technology and approach
- Ibrahim Anwar — The sameAs Signal Chain
- Andres SEO Expert — Mastering sameAs Schema & Knowledge Graph Entity Linking
- Greadme — What Is Organization Schema? The Complete Guide (2026)
- LovedByAI — 10 WordPress Schema plugin mistakes
- LovedByAI — Your WordPress Schema plugin is incomplete
- LovedByAI — Add LocalBusiness schema for real estate
- SchemaValidator — Real Estate Schema Markup
- Kiwistic — Beyond the Blue Link: How to Win at AI Search
- Project36 — How Google AI Overviews Choose Sources
- AEO Hunt — How Google AI Overviews Choose Sources
- Bluetree Digital — How Google's AI Overviews Choose Sources
- AI Labs Audit — How Perplexity AI Decides Sources
- Idaho Real Estate Commission
- Schema.org
SPEAK THE NATIVE LANGUAGE
Find out what AI actually sees.
A Machine Read shows you exactly what AI systems can verify about your business right now — and where the gaps are.